System CPU and glibc
August 13, 2021
TLDR
This article discusses the high level details with std::vector, glibc and
how allocating large memory regions impact CPU usage under extreme CPU and
memory pressure.
As a gist, prefer direct mmap with MAP_POPULATE|MAP_SHARED|MAP_ANONYMOUS
over std::vector or malloc that uses mmap internally with
MAP_PRIVATE|MAP_ANONYMOUS.
Continue to read if still interested in the details.
Why is the kernel eating my cake?
We recently rewrote one of our legacy large scale biometric matcher product (a custom map-reduce implementation) that uses multi-process architecture to multi-threaded architecture so that it uses less resource to run in a docker container on Kubernetes as the per-process overhead can be eliminated. We rolled this out to few cloud deployments with smaller gallery sizes in the order of hundreds of thousands and it all went well. At least until we pushed the system to it’s limits and increased the gallery sizes to tens of millions.
On a host machine with 96 core and 256 GiB RAM, 235 GiB was filled with the
gallery to be searched and each of the CPU core was affined to a search worker
thread so that the searches are efficient. The default tmpfs on the host was
untouched and was left at 50% (128 GiB) on /dev/shm/ where POSIX shared memory
is managed. System swaps were turned off to ensure there are not major page
faults. The docker container loaded all the datasets from the file system
without any hiccups. The expectation was the response time per request will be
around 11 seconds per core/request as the algorithm skims through the datasets,
looking for a biometric match. When the performance/load tests were started with
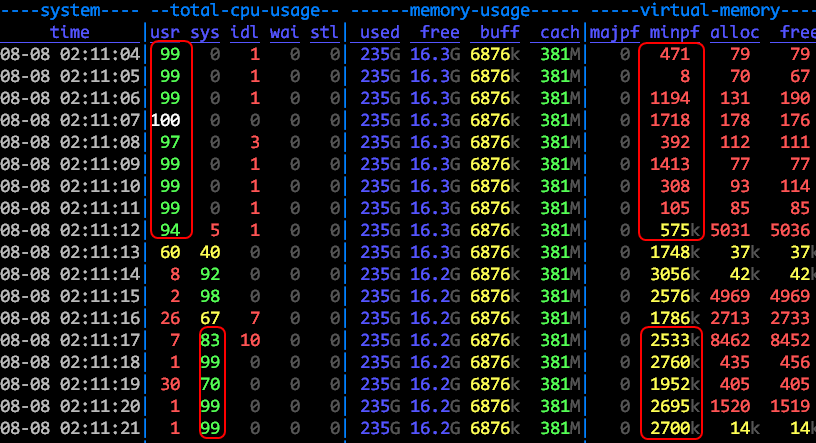
96 concurrent search requests, system/kernel CPU usage spiked up and in
turn increased the response latencies by 10 folds. We anticipated to see ~1%
system CPU usage as we had carefully designed all the memory allocations and
locking strategies to ensure there are no page-faults. But it turned out to be
false.
It was initially an intriguing observation as this behaviour was not observed with the multi-process architecture that’s running rock solid across various data centers in the world. But the root cause became clear as the request concurrency was gradually increased from 10, 20, 40, 60, 80 and 96. When the concurrency was gradually increased, the kernel CPU didn’t spike up and the response time average and standard deviation stayed pretty low and consistent across runs when we hit the peak concurrency of 96. It continued to stay consistent for over an hour without any problem.
But why?
Major page faults cannot be the influencing factor since the swaps were turned
off. There was a clear correlation between kernel CPU usage spike,
awk '{print $10}' /proc/$(pidof X)/stat and dstat --vm. The minor page
faults were in the order of 2500k. This is way over the average 500 limit.
We figured that the page table translation failures and TLB
misses causes
minor page faults in the kernel and the CPU cycles were spent to populate the
page table.
But why?
Since the app that runs in the container is multi-threaded, naturally the
tendency is to think that std::vector is the ideal container of choice to
store the gallery in memory. Unless it is resized it doesn’t reallocate and
expand the virtual memory region by a factor of two. The use case and the
decision was to allocate once and to NEVER resize it, ever. Thus the memory
was better optimized and the CPU usage was as well. This is mostly true, but not
for high performance computing systems, as noted below.
What happens under the hood of std::vector is interesting. At least at the time of
writing this article, with Linux kernel 5.4.0 and GLIBC 2.31, the default
allocator of std::vector uses malloc and that in turn uses brk system call for
small memory allocations and mmap for large memory allocations.
This can be asserted with a fooboo:
#include <cstring>
#include <vector>
int main() {
// change size to 131049 and mmap will be used
long long size = (long long)127 * 1024;
std::vector<char> a(size);
memset(a.data(), 0, a.size());
return a.size();
}
Compule and run this with:
g++ a.cpp -o a && strace ./a 2>&1 | tail
And this will be observed.
...blabla...
brk(NULL) = 0x559722562000
brk(0x559722583000) = 0x559722583000
brk(0x5597225b4000) = 0x5597225b4000
brk(0x559722594000) = 0x559722594000
exit_group(131048) = ?
+++ exited with 232 +++
As long as size is less than or equal to 127 KiB (precisely 131048 bytes), per
allocation, glibc will expand the heap using the brk system call. If it is 1
byte more than that, it will use mmap with MAP_PRIVATE|MAP_ANONYMOUS to get
the heap memory. 127 is again a magic number because the memory allocator
tracks the number of 1 KiB pages per allocation in a signed char data type. On
exceeding that, it uses mmap instead of brk to expand the heap region of the
process.
$ g++ a.cpp -o a && strace ./a 2>&1 | tail
...blabla...
brk(NULL) = 0x55646c547000
brk(0x55646c568000) = 0x55646c568000
mmap(NULL, 135168, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x7f2e9f214000
munmap(0x7f2e9f214000, 135168) = 0
exit_group(131049) = ?
+++ exited with 233 +++
When using straight malloc/calloc, the size after which mmap is preferred over
brk is 134472 bytes (131 KiB + 328 bytes). I do not know why.
#include <cstdlib>
#include <cstring>
int main() {
// change 328 to 329 and mmap will be used
long long s = (long long)131 * 1024 + 328;
char *p = (char *)calloc(1, s);
memset(p, 0, s);
return p[100];
}
With (131 * 1024 + 328) bytes:
$ g++ a.cpp -o a && strace ./a 2>&1 | tail
...blabla..
brk(NULL) = 0x55b7c053a000
brk(0x55b7c055b000) = 0x55b7c055b000
exit_group(0) = ?
+++ exited with 0 +++
With (131 * 1024 + 329) bytes:
$ g++ a.cpp -o a && strace ./a 2>&1 | tail
...blabla...
brk(NULL) = 0x5638e63ab000
brk(0x5638e63cc000) = 0x5638e63cc000
mmap(NULL, 135168, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) =
0x7f249d2f0000
exit_group(0) = ?
+++ exited with 0 +++
So what?
Our biometric datasets are sized at 1 GiB for easier file management as we could
turn on transparent huge pages, if required. So it is guaranteed that mmap is
being used under the hood by std::vector, so why was there page table misses in the
first place? That’s because the MAP_PRIVATE flag instructs the kernel to
turn off VM_SHARED flag when creating the mapping in the kernel. This causes
page tables and TLB to be cold and populate it only on demand, via page faults.
As long as this translation is small, there’s no overhead. However as the memory
pressure increases with concurrency, the kernel has to fight hard to populate
the page tables and TLB.
To the kernel, all the processes and the threads within a process are tasks.
When VM_SHARED is set via MAP_SHARED from the user space, the kernel ensures
the mapping is shared across tasks with their page tables populated as well. This
includes threads within a single process. All the books, articles and resources
use the term process in the context of task, but misses the whole point and
fail to explain this critical difference.
When MAP_SHARED is used, the initial process/task creation could be
fractionally slower as the page tables gets filled. However once the page tables are hot, the
worker threads will be ready to rock and roll and the address translation is the
only overhead they will have to endure. This will not cause any page faults.
This was never a problem in the multi-process architecture as they always communicated through shared memory with hot page tables.
The book “Understanding the Linux Kernel” goes in depth in explaining the finer details about how it is implemented in the kernel in the Memory Management (chapter 8) and Process Address Space (chapter 9). It is a must read for curious programmers on Linux (even when not programming in kernel).
The fix
There are multiple ways in which this problem can be addressed. We settled on a
simple solution to directly use mmap with MAP_SHARED with a RAII wrapper.
That did all the trick as we didn’t have to support resize as a use case. For
what it is worth, boost::interprocess library has this nifty little wrapper
called mapped_region that does this job perfectly, in conjunction with
anonymous_shared_memory function. Since the mapping is within a process and
not across processes, MAP_ANONYMOUS was preferred. If it were across
user-space processes, the MAP_ANONYMOUS flag should not be used and an
underlying file descriptor (probably via shm_open, or open) shall be used
with mmap. That’s how shared memory implementations in the kernel work, as the
user-space processes just need to have a file name as common reference.
The change was deployed and voila, the performance is back to normal as if operating with smaller gallery. Overall resource usage was much less than the multi-process architecture as the per-process overhead has been eliminated.
Summary
I really like the way these seemingly semantically unrelated, but
humanly related flags MAP_PRIVATE and MAP_ANONYMOUS are named
appropriately by the standards.
MAP_PRIVATE: Private from the perspective of a processMAP_ANONYMOUS: Anonymous from the lack of file behind the mapping
In layman terms, it’s like saying, I want to keep my things private to myself and I don’t want to share with the outside world. But if I do want to share, I will write to a personal diary (file). I will also stay anonymous, so that others won’t know who I am or that I even exist and thus my diary/file can’t be correlated to me. I’m quite sure everyone can concur with this in this current world where online privacy and anonymity are a lost dream.
That aside, the reasoning behind glibc allocator’s use of mmap with
MAP_PRIVATE|MAP_ANONYMOUS as defaults, is privacy and anonymity. Which makes
sense, because we do not want other processes to peak into the memory region of
our process. That would be a security nightmare. But I’m not sure I agree on
this for inter-thread design. Threads inherently share the same process space
and thus the heap. MAP_PRIVATE gets a copy-on-write mapping for performance
reasons (may be). MAP_ANONYMOUS will ensure the mapping is initialized to
zero. So the performance optimization is wasted away. However this doesn’t make
sense for user-space data structures std::vector or malloc for that matter
(FWIW, malloc, although a function, has it’s own internal data structure under
the hood). No one is going to throw away a memory region after allocation
without writing something into it, after all, why else will they allocate in the
first place? As the size of memory being requested is large, it makes sense to
use MAP_SHARED|MAP_ANONYMOUS as the default in glibc.
Edit
- As pointed out in HN thread, both page table misses and TLB misses cause page faults, not just TLB misses. However NUMA was not a problem, as THP defragmentation has been disabled.
- Upon further research I found that
MAP_POPULATEgets the job done. The work around of usingmmapinstead ofstd::vectoris still a valid choice andMAP_SHAREDskipped in favour of that.